Downmixing of surround sound material from multichannel (typically
the 5.1 channel format) to two-channel stereo or mono is 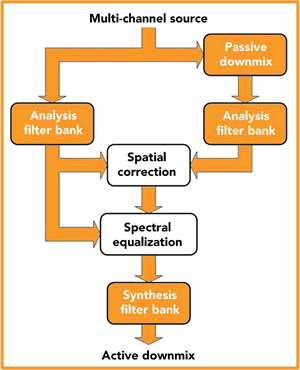 often
necessary for a variety of reasons, such as to accommodate surround
sound transmission over an analog FM, two-channel stereo radio
signal. For example, Minnesota Public Radio announced in October
that, in partnership with the Minnesota Orchestra and surround
sound company DTS, Inc. (Agoura Hills, Calif, www.dts.com)
the 2009 concert season will be broadcast over analog FM radio
in full 5.1 surround sound (see http://minnesota.publicradio.org/radio/services/cms/dts.shtml
for additional information on this announcement). Other stations,
including classical radio WGUC (90.9 MHz, Cincinnati, OH) and
jazz radio KUVO (89.3 MHz, Denver, CO) regularly broadcast surround
sound audio.
often
necessary for a variety of reasons, such as to accommodate surround
sound transmission over an analog FM, two-channel stereo radio
signal. For example, Minnesota Public Radio announced in October
that, in partnership with the Minnesota Orchestra and surround
sound company DTS, Inc. (Agoura Hills, Calif, www.dts.com)
the 2009 concert season will be broadcast over analog FM radio
in full 5.1 surround sound (see http://minnesota.publicradio.org/radio/services/cms/dts.shtml
for additional information on this announcement). Other stations,
including classical radio WGUC (90.9 MHz, Cincinnati, OH) and
jazz radio KUVO (89.3 MHz, Denver, CO) regularly broadcast surround
sound audio.
While a number of standardized, passive methods exist for downmixing
that utilize static coeffients for combining the various multiple
channels, a paper given in October at the 127th Convention of
the Audio Engineering Society (AES, New York, NY, www.aes.org)
described a new, dynamic downmixing approach which minimizes various
distortions commonly observed in passively downmixed audio such
as spatial inaccuracy, timbre change, signal coloration, and reduced
intelligibility.
This paper, entitled An Active Multichannel Downmix Enhancement
for Minimizing Spatial and Spectral Distortions, was authored
by Jeffrey Thompson, Aaron Warner, and Brandon Smith of DTS, Inc.
The authors propose a time-varying and frequency-dependent downmix
processing scheme (shown in the block diagram at right) based
on detecting and correcting for unsatisfactory conditions.
Heres how this scheme works: a passive downmix of the multichannel
source material is first generated. Next, the source and passively
downmixed channels are converted to the frequency domain using,
for example, a short-time Fourier transform. This frequency domain
information is processed using a spatial correction algorithm
(represented by the upper white block in the diagram) which analyzes
relevant spatial characteristics of the source and passive downmix,
and corrects any spatial inconsistencies identified in the downmix
through modifications to the inter-channel level difference (ICLD)
and inter-channel phase difference (ICPD) characteristics used
in the downmix description.
Finally, a spectral equalization algorithm (lower white block)
analyzes the source and the spatially-corrected downmix and 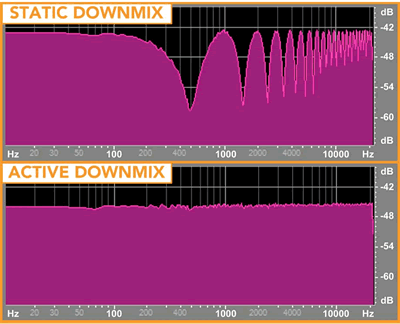 normalizes
the power of the downmixed spectrum to the power of the source
spectrum. In the AES paper, the performance of the proposed active
downmix was evaluated based on correction of spatial inaccuracies
and reduction of timbre anomalies within a matrixing system. An
Lt/Rt downmix with alpha set to 30 degrees was used for the passive
downmix, and a commercial DTS Neural Surround decoder was used
as a reference matrix decoder.
normalizes
the power of the downmixed spectrum to the power of the source
spectrum. In the AES paper, the performance of the proposed active
downmix was evaluated based on correction of spatial inaccuracies
and reduction of timbre anomalies within a matrixing system. An
Lt/Rt downmix with alpha set to 30 degrees was used for the passive
downmix, and a commercial DTS Neural Surround decoder was used
as a reference matrix decoder.
An example of the spectral equalization improvement offered by
active downmixing is shown in the figure. For this example, the
original audio consists of white noise in the center channel with
time delayed white noise in the left and right channels (different
time delay for each channel). The top image shows the spectral
content resulting from a static downmix of this material clearly
evident is the comb filtering resulting from the time delay
difference between the left and right channels. The lower spectral
image is from the same material resulting from an active downmix
which resulted in significantly less distortion.
The full AES paper discussed here is available for purchase from
the AES go to www.aes.org/e-lib/browse.cfm?elib=15108
for additional information.
ADVERTISEMENT

|
